統計の基礎やってみた【やさしく学ぶデータ分析に必要な統計の教科書】#002
こんにちは!こーたろーです。
今日は、統計学の基礎をやってみます。
というよりは、統計学のやさしめの教材を学びつつ、データサイエンスに必要な探索的データ分析(EDA)の練習を兼ねています。
是非、皆さんもやってみてくださいね。
教材は【やさしく学ぶ データ分析に必要な統計の教科書 できるビジネスシリーズ】を使用します。
早速トレーニング!
データは前回のブログで紹介したものと同じものを使用します。
参考:統計の基礎やってみた【やさしく学ぶデータ分析に必要な統計の教科書】#001 - 福岡の社会人データサイエンティストの部屋
せっかくなので、初めからやってみます。
必要なライブラリのインポート
import numpy as np import pandas as pd import matplotlib.pyplot as plt #matplotlib inline
データの読み込み、表示
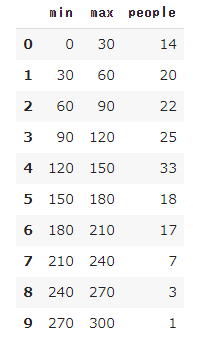
sample_df = pd.read_csv('2.csv' , sep=',') sample_df
【操作2-1】 分布の上限と下限を確認
a = sample_df['minutes'].max() b = sample_df['minutes'].min() print('max is {0}, min is {1}'.format(a,b))

【操作2-2】 階級数の幅を求める
今回は、最大値287、最小値10ということで、2桁目を丸めて0と300とし、階級を300とします。
これを表現すると、
a = round(a,-2) b = round(b,-2) print('a is {0}, b is {1}'.format(a,b) )

階級数を10とすると、各階級の幅は
number_division = 10 number_class =round((a-b)/number_division,0) print(' number of class is {0}'.format(number_class))

【操作2-3】階級を設定する
0~30までの階層を作成していきます。
min_columns = np.array(list(range(b,a,number_class))) max_columns = min_columns + number_class min_columns = min_columns.reshape(-1,1) max_columns = max_columns.reshape(-1,1) class_frame = np.append(min_columns,max_columns,axis=1) class_df = pd.DataFrame(data=class_frame,columns=['min','max']) class_df = pd.DataFrame(data=class_frame,columns=['min','max']) class_df['people'] = 0 class_df
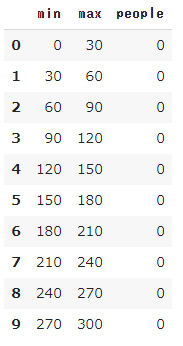
これでデータ格納用のデータフレームが完成しました。
あとは、分布を入れていきます。
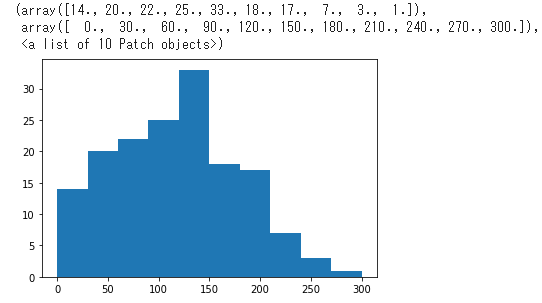
【操作2-4】【操作2-5】度数分布表を作成する
データを格納する関数を定義します。
def sep_class(i,min_value, max_value): class_df.loc[i]['people']=((sample_df['minutes'] >= min_value) & (sample_df['minutes'] < max_value)).sum() return
各クラス階級ごとに実行します。
for i in range(len(class_df)): min_value = class_df.loc[i]['min'] max_value = class_df.loc[i]['max'] sep_class(i, min_value,max_value) class_df