機械学習でコストダウン???【コラム】#008
こんにちは!こーたろーです。
なんだか春が近づいたかと思えば雪降ったりで、体調崩しやすい環境ですが、皆さん元気にされていますか?
もう2月も半分すぎて、そろそろ年度末の処理や新年度の準備が始まりますね。
さてさて、今日の話題はコチラです!
「機械学習でコストダウン」というところに、私は惹かれました。
なぜかというと、AI分野といえば、機械学習や深層学習で、付加価値を生み出すというイメージが、私の中であっため、コスト削減のイメージがあまりわかなかったからです。
さて、Dropboxではいかにしてコストダウンを達成したのでしょうか。
Dropboxが自社サービス上の「ファイルプレビュー機能」を機械学習で効率化することで、170万ドル(約1億7000万円)の費用削減を達成しました。
なぬっ!意味が分からない・・・・汗
Dropboxは昔、関係者でファイル共有する時などに使用したことがありますが、その時のファイルプレビューでしょうか。
Dropboxはアップロードされたファイルを素早くプレビューするため、「Riviera」という内部システムを利用して事前にファイルのプレビューデータを生成しているとSuen氏は説明。しかし、事前に生成したデータが利用されず無駄になるケースもあったため、機械学習で事前生成すべきデータを予測し、データ生成時のマシンリソースを節約するプロジェクト「Cannes」が発足することになりました。
つまり、マシンリソースを減らすことで、コスト削減を行っているということですね。
実際にマシンリソースが削減されているわけですから、
「利用されず無駄になるマシンリソース」>「機械学習を用いる際のマシンリソース」
になっているということですね。
それだけこの利用されず無駄になるプレビューデータがあったということでしょう。
開発チームは、「予測が外れた場合のパフォーマンス低下の許容範囲」と「機械学習モデルのシンプルさ」を重視して開発を進めたようで、これが上記の比較を得る決定的な部分になったと考えられます。
こういう実際の活用例で注目すべきはデータセットやモデルの情報を知りたいものですが、記事によると
【データセット】
- 「ファイルの拡張子」
- 「保存しているファイルの種類に基づくアカウントの区分」
- 「直近30日間におけるアカウント利用状況」
【モデル】
- 勾配ブースティング
【テスト】
- 本番環境のトラフィックを利用したA/Bテスト
システムアーキテクチャも公開されています。
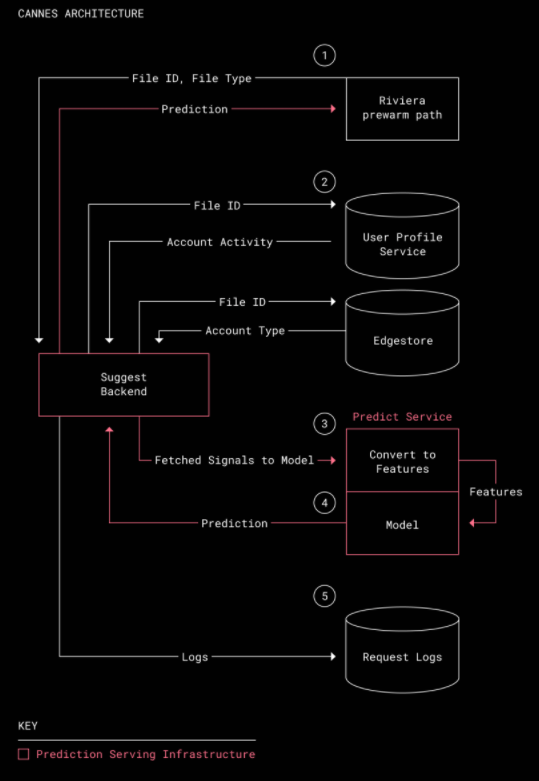
開発チームが目指したシンプルさが伝わってきますね。
開発チームはプレビューデータの事前生成にかかる年間コストを試算通り、約1億7000万円も削減。Cannesの運用にかかる費用は年間9000ドル(約90万円)であるため、非常に大きなコストカットを達成できていることがわかります。開発チームは今後、より複雑なモデルを実験して予測精度の向上を目指すほか、特徴量に対する重みを再学習させ、モデルを微調整する「ファインチューニング」を行う予定だそうです。
こちらは大幅なコストカットを実現した非常にいい事例だと思います。
今後も、このような情報を収集して、皆さんに紹介できればと思います。
ではでは。
