【医療画像AI】X線胸部画像から性別を予測してみた#005
こんにちは!こーたろーです。
今回もまた、日本放射線技術学会 画像部会のページから、正解ラベルのあるX線胸部画像データから性別を予測する分類問題を解いていきます。
今回は、正解データのファイルがtxtファイルになっていることに注意します。
久しぶりにPythonをやっているのですが、CNNの勉強をし出すと、結構奥が深いことが分かってきます。
あと言えることは、ローカルでやっていると、私の現在のPCでは火が噴きそうなぐらいファンが回っていることですかね。
そろそろ買い替え時かもしれません。
- 必要データのダウンロード
- ライブラリ・オブジェクトのインポート
- データの前処理その1(データ情報のロード)
- データの前処理その2(画像データ)
- データの前処理その3(正解ラベル)
- モデルの構築・学習
- テストデータでの評価
必要データのダウンロード
いつもの通り、サンプルとなるデータ及び正解ラベルの入ったファイルを準備していきます。
サンプルデータが日本放射線技術学会 画像部会のページからダウンロードできます。
http://imgcom.jsrt.or.jp/imgcom/wp-content/uploads/2018/12/Gender01_Index.zip
ダウンロードしたら、解凍を行ってください。
すると、「train」「test」「list_train.txt」「list_test.txt」と2つのフォルダと2つのテキストファイルができますので、pythonファイルのレイヤーに保存してください。
ライブラリ・オブジェクトのインポート
最近はCNNとその前処理ばかりですので、使うライブラリもおなじみとなってきました。
以下のライブラリ・オブジェクトをインポートしてください。
import pandas as pd import numpy as np import matplotlib.pyplot as plt from keras.preprocessing.image import load_img, img_to_array from tensorflow.python.keras.utils import to_categorical from sklearn.metrics import accuracy_score, confusion_matrix from tensorflow.python.keras.models import Sequential from tensorflow.python.keras.layers import Conv2D from tensorflow.python.keras.layers import MaxPooling2D from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Flatten from tensorflow.python.keras.layers import Dense
今回は2値分類ですが、せっかくなのでCNNで出力で男性・女性をそれぞれ測定してみます。
データの前処理その1(データ情報のロード)
今回は、正解ラベルデータがtextファイルですので、pd.read_tableを使用します。
この時、headerが今回のファイルに存在しないことに注意し、読み込みます。
データフレームになっているので、カラムだけわかりやすいように変更しておきます。
train_data = pd.read_table("./list_train.txt",header = None, delimiter =',') train_data = train_data.rename(columns={0:'FPass', 1:'Sex'}) test_data = pd.read_table("./list_test.txt", header = None, delimiter =',') test_data = test_data.rename(columns={0:'FPass', 1:'Sex'})
データの前処理その2(画像データ)
データ情報をロードしたら、その情報からファイル名(ファイルパス)が分かるので、ファイルごとの画像データを取得していきます。
【学習用データ】
trainImg = np.zeros((len(train_data["FPass"]), 128, 128, 1)) for i in range(0, len(train_data["FPass"])): fname = '%s' %train_data["FPass"][i] trainImg[i] = np.array(img_to_array(load_img(fname, color_mode = "grayscale", target_size=(128,128))))/255.0 trainImg.shape
![]()
今回は、128×128ピクセル×1チャネル(グレースケール)画像を取り扱っていくことが分かります。
また、トレーニングデータは154枚の画像であることも確認できます。
【テスト用データ】
testImg = np.zeros((len(test_data["FPass"]), 128, 128, 1)) for i in range(0, len(test_data["FPass"])): fname = '%s' %test_data["FPass"][i] testImg[i] = np.array(img_to_array(load_img(fname, color_mode = "grayscale", target_size=(128,128))))/255.0 testImg.shape
![]()
テストデータは、93枚で、その他の次元は同じとなっています。
データの前処理その3(正解ラベル)
正解ラベルを作成していきます。こちらは初めにロードしたデータから取得します。
データを確認すると、「male」と「female」の表記になっていますので、「male」=「0」、「female」=「1」と置き換えを実施します。
trainSex = train_data["Sex"].values trainSex = trainSex.reshape(len(trainSex),1) trainSex = np.where(trainSex == "male", 0, 1) Onehot_label_train = to_categorical(trainSex, 2) testSex = test_data["Sex"].values testSex = testSex.reshape(len(testSex),1) testSex = testSex testSex = np.where(testSex == "male", 0, 1) Onehot_label_test = to_categorical(testSex, 2)
最後に、学習用ラベル・テスト用のラベル共にone-hotベクトル化しておきます。
モデルの構築・学習
モデルは、いつものようにCNNを構築していきます。特徴抽出は
「畳み込み層」×「畳み込み層」×「プーリング層」×「ドロップアウト」×「畳み込み層」×「畳み込み層」となっています。
また、予測部分については、「全結合層」×「ドロップアウト」×「全結合層」としています。
出力の活性化関数は、分類ということもあり、softmax関数を用いています。
model = Sequential() model.add(Conv2D(filters = 32,input_shape = (128, 128, 1),kernel_size = (3, 3), strides = (1, 1),padding = 'same',activation = 'relu')) model.add(Conv2D(filters = 32, kernel_size =(3, 3), strides = (1, 1),padding = 'same',activation = 'relu')) model.add(MaxPooling2D(pool_size =(2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(filters = 64,kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(Conv2D(filters = 64, kernel_size =(3, 3), strides =(1, 1), padding = 'same', activation = 'relu')) model.add(MaxPooling2D(pool_size =(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(units=512, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units= 2, activation='softmax'))
モデルの構築はこのような形にしています。
出力のノードが2であるのは、男性か女性かの出力を出すためです。
なお、1でも大丈夫ですが、前処理を少し変えないといけません。(ワンホットしたのが悪い?)
よく考えたら、One-hotベクトル化した時点で二つのカラムのvalueは全て同じになりますね。。。以後気を付けます。
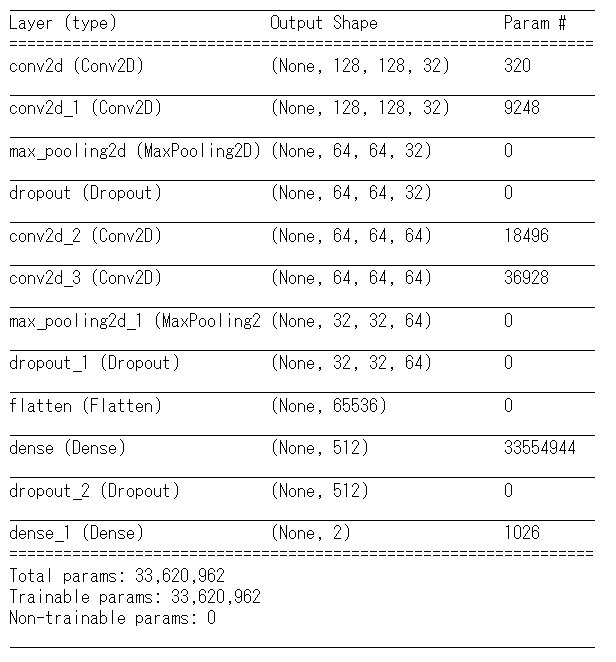
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',metrics=['accuracy']) model.summary()
モデルをコンパイルしてサマリを見てみます。
なお、損失関数は、loss='sparse_categorical_crossentropy'を利用していますが、CNNの出力を1としている場合は、binary_crossentropyを使ってください。
それでは、実際に学習をさせていきます。
hist = model.fit(trainImg,trainSex,
batch_size=8,epochs=50,
validation_split=0.2,verbose=1)

validationの正答率で93.5%でていますね。少し期待できそうです。
テストデータでの評価
valsex = model.predict(testImg) valsex = np.where(valsex >0.5,1,0)
作成したモデルにテストデータを入れていきます。
予測した結果は、確率ででてくるためしきい値を0.5として0、1の2値に直します。
results = list(model.predict_classes(testImg, verbose=1)) cmatrix = confusion_matrix(testSex, results) print(cmatrix) score = accuracy_score(testSex, results) print(score)
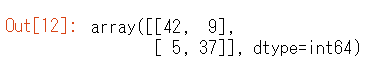
![]()
学習用のデータのvalidation正解率は95%程度でしたが、テストデータにおいては、85%と10ポイント下がっていました。
この精度がいいのか悪いのかよく分かりません・・・今度、検定をやってみて有効かどうかを確認してみたいと思います。
ではでは。
