【RandomForest】ワインの美味しさ評価(改良版)【Python】
こんにちは!こーたろーです。
前回のワインの美味しさ評価では、正答率が67%と低かったため、考察を行ってみましたが、分類問題において11分類問題での正答率は難しいことが分かりました。
今回は、この評価分類を改善することによって、もう少しラベルを簡略した改善モデルについてハンズオンをやってみました。
前処理については、いろいろとありましたが、今回warningは気にせず行っていきます。
それでは早速始めていきましょう。
必要データのダウンロード
前回ダウンロードして保存した方はこちらは省略してください。
前回同様、こちらの白ワインのデータを使用します。
https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality
リンクを実行するとファイルがダウンロード開始すると思います。
from urllib.request import urlretrieve url = "https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv" savepath = "winequality-white.csv" urlretrieve(url, savepath)
Pythonのファイルと同じフォルダ内にダウンロードします。
ワインデータの確認
データのダウンロードしたら、ファイルをPythonでロードしてデータフレームとして表示してみます。
import pandas as pd wine = pd.read_csv('winequality-white.csv', encoding="utf-8", sep = ";") wine
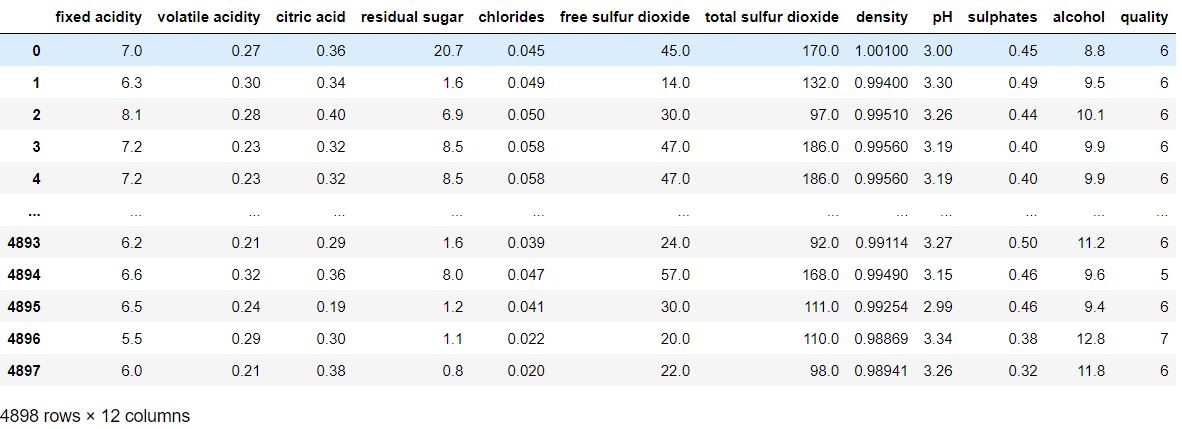
4898個のデータセットがあることが分かります。
12カラムのうち、quality(品質)が目的変数となります。
それ以外の11カラムが説明変数です。
正解ラベルについて、ヒストグラムで確認していきます。
import matplotlib.pyplot as plt plt.figure(figsize = (10,3)) plt.hist(wine["quality"] , bins=11, range = (0,10)) plt.title("y_train histgram") plt.xlabel("Quality") plt.ylabel("Number of Count") plt.grid(True) plt.tight_layout()
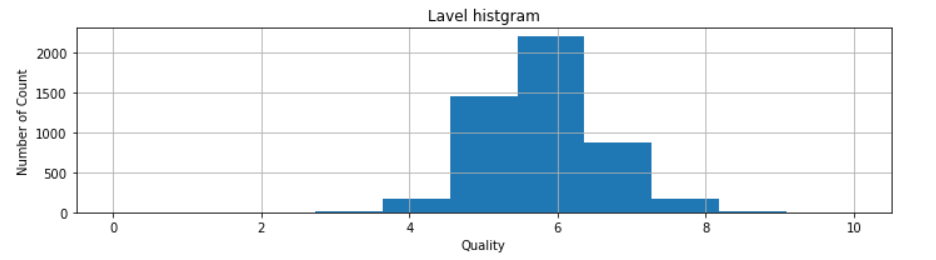
ヒストグラムを確認すると、正規分布っぽい形をしています。
こちらのカウント数を確認します。
wine.groupby("quality")["quality"].count()
groupbyを使って、[quality]のカラムを値別にカウントします。

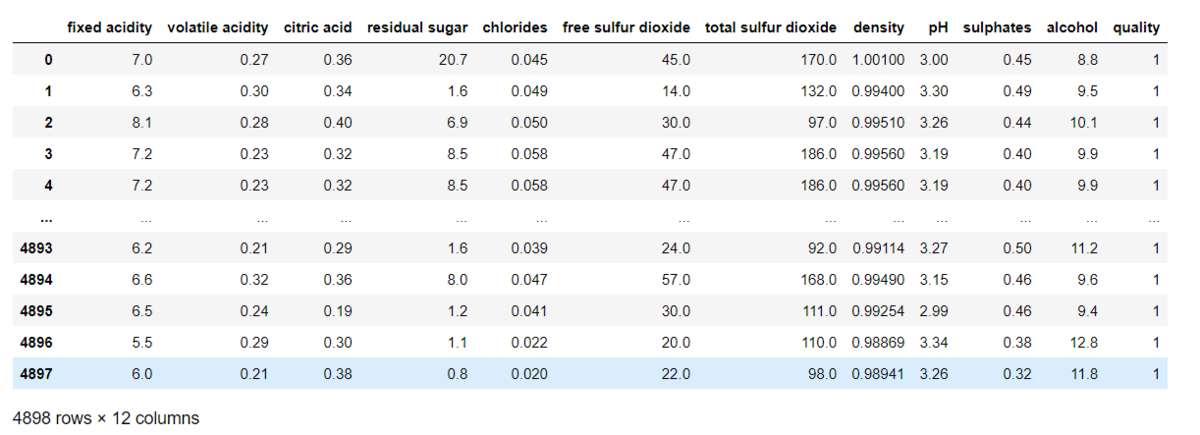
ここで、11段階のラベルを見直して、3段階にしていきます。
具体的には、評価が4以下の場合は0,5から7は1、8以上は2というラベルを付けていきます。
つまり、評価が
0-4 ⇒ 美味しくない : ラベル0
5-7 ⇒ 普通 : ラベル1
8-10 ⇒ 美味しい : ラベル2
としてラベルを再定義します。
for i in range(len(wine["quality"])): if wine["quality"][i] <=4: wine["quality"][i] = 0 elif wine["quality"][i] <=7: wine["quality"][i] =1 else: wine["quality"][i] = 2 wine
あまり、直接データを上書きすることはお勧めしませんが、警告が出つつも早く結果が知りたいので今回は荒々しく実行しました
データの前処理
以降は、前回とほぼ同じコードで実行します。
学習データとテストデータを作成していきます。
scikit-learnの「train_test_split」にてデータを分割します。
from sklearn.model_selection import train_test_split x = wine.drop("quality", axis = 1) y = wine["quality"] x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2)
データフレームを説明変数(x)と目的変数(y)に分割します。
その後、x,yそれぞれを80%が学習データ、20%がテストデータとして分割します。
モデルの作成(RandomForest)
続いてモデルを作成していきます。
前回と比較するためモデルもそのままです。
from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier() model.fit(x_train,y_train)
ランダムフォレストのオブジェクトを作成して、fitメソッドで学習データでの学習を行います。
モデルの評価
最後にモデルを評価していきます。
学習済みのモデルに対して、predictメソッドにてテストデータの説明変数を代入することで、目的変数を予測していきます。
今回使用したデータは、品質を0~2の3段階として評価しております。
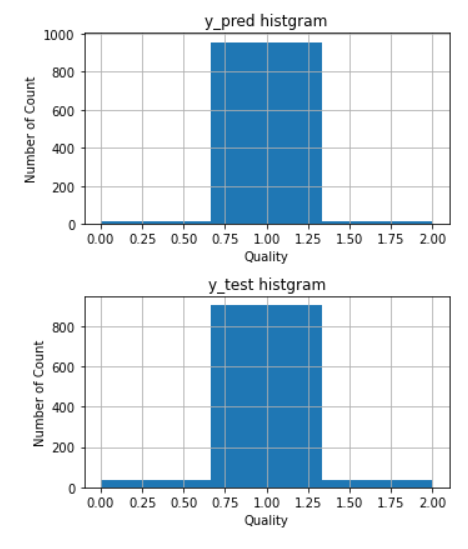
from sklearn.metrics import accuracy_score, classification_report import numpy as np y_pred = model.predict(x_test) y_test = np.ravel(y_test) print(classification_report(y_test, y_pred)) print("accuracy = ", accuracy_score(y_test, y_pred))

正答率は94%とかなり改善したことが分かります。
plt.figure(figsize = (5,6)) plt.subplot(2,1,1) plt.hist(y_pred, bins=3, range = (0,2)) plt.title("y_pred histgram") plt.xlabel("Quality") plt.ylabel("Number of Count") plt.grid(True) plt.subplot(2,1,2) plt.hist(y_test, bins=3, range = (0,2)) plt.title('y_test histgram') plt.xlabel('Quality') plt.ylabel('Number of Count') plt.grid(True) plt.tight_layout()
グラフも確認します。
今回は、ワインの美味しさ評価を改良した正解率の高いモデルを作成してみました。
機械学習ハンズオンの基礎トレーニングとしてどうぞ活用ください。
ではでは。
