Tensorflow で手書き文字識別 【図解速習Deep Learning】 #002
こんにちは。 こーたろーです。
本日は、【図解速習DEEP LEARNING】 の第2章です。
第2章では、Tensorflowで手書き文字識別を行っています。
他の本でもよくあるMNISTのデータで分類ですね。
早速やってみました。
環境は Google Colaboratory で、Python3、GPU使用でやっていきます。
Tensorflowチュートリアル を利用したコーディングとなります。
では早速。
1.ライブラリーのインポート
import tensorflow as tf from matplotlib import pyplot import numpy as np import pandas as pd
2.MINISTデータセットのロード
mnist = tf.keras.datasets.mnist (x_train, y_train), (x_test, y_test) = mnist.load_data()

3.データの形を確認してみる
print(x_train.shape) print(y_train.shape) print(x_test.shape) print(y_test.shape)

4.MINISTの文字画像を読みだして表示
for i in range(0, 64): pyplot.subplot(8, 8, i + 1) pyplot.imshow(x_train[i], cmap='gray') pyplot.show()

このデータがロードされるのですね。。。
TensorflowのMNISTのデータをソース内で表示させている例は少なかったので、載せてみました。
5.サンプルを不動小数点に変換。(標準化したものと一緒になる)
x_train, x_test = x_train / 255.0, x_test / 255.0
6.モデルを作成
model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10) ])
今回は、28×28の2次元画像データ(白黒)をインプットとし、全結合で学習。活性化関数はrelu。
7.それぞれの標本について、クラスごとにロジットを算出
predictions = model(x_train[:1]).numpy()
predictions

8.ロジットを確率へ変換
tf.nn.softmax(predictions).numpy()

9.損失関数を設定
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) loss_fn(y_train[:1], predictions).numpy()

10.モデルをコンパイル
model.compile(optimizer='adam', loss=loss_fn, metrics=['accuracy'])
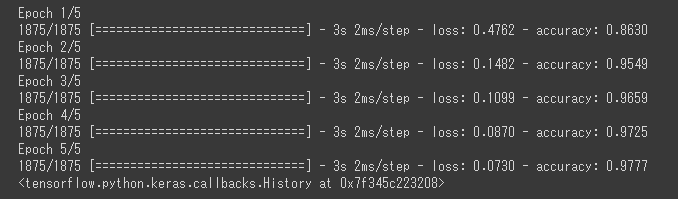
11.trainデータで学習させてみる
model.fit(x_train, y_train, epochs=5)
12.モデルへtestデータを入力して、評価してみる。
model.evaluate(x_test, y_test, verbose=2)

98.0%程度の精度で分類できている模様。。
っと、大抵の資料ではここまで。でもよく考えてみると、最終的にどうやって判断しているのだろうか。と疑問になりませんか?
ということで、
13.予測結果を呼び出してみる
X = pd.DataFrame(X) Y = pd.DataFrame(y_test)
X、Yはどうなっている?
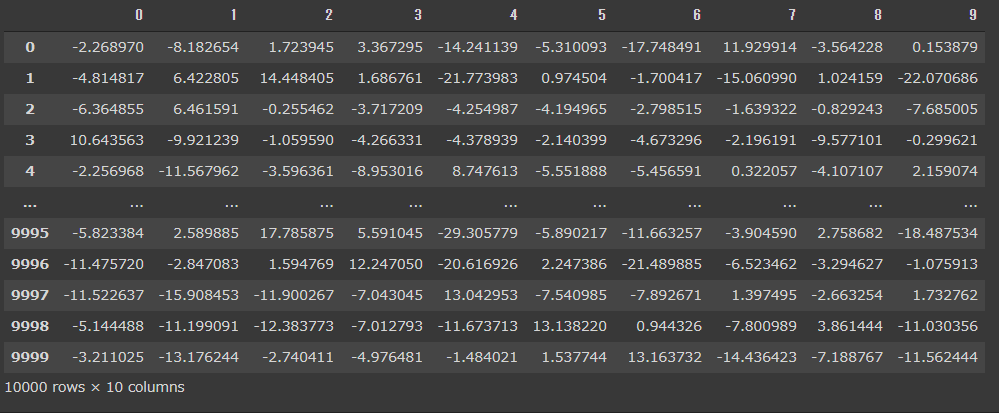
X
Y
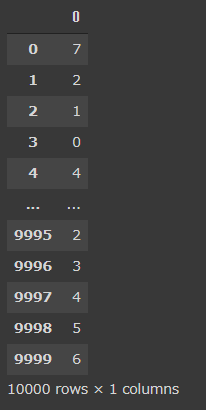
こう見ると、predictで得られたデータは、値の確率であり、そのもっとも高い値に該当するColumnsの値(0~9のいずれか)である可能性が高いということである。
例えば、Xの1行目を見ると、確立が一番高いのは7(11.530725)であり、Yの1行目の正解ラベルは7である。
2行目は、確立が一番高いのは2(12.971532)であり、Yの2行目の正解ラベルは2となっている。このように識別を行い、正解ラベルと正誤を比較した結果、98.0%の正解率となっているということである。
なるほどなるほど。
今回はハイパーパラメータは変更していませんが、そのうちやってみたいと思います。
ではでは。