mimi-APIで音声認識試してみた!【図解速習DeepLearning】#018
こんにちは!こーたろーです。
Deep Learning の2021年度の学習計画をそろそろ立てようかと思っています。
いい参考書などありましたら教えて頂けると幸いです。
それでは今回も【図解速習DEEP LEARNING】やっていきます!
今日は、「mimi」というWebAPIサービスを利用していきます。
こちらは、フェアリーデバイセズ株式会社が提供しているものです。
mimiのアカウント作成
mimiのサイトに飛びます。URLは以下のようになっています。
mimi®️ | 音声AIの総合プラットフォーム
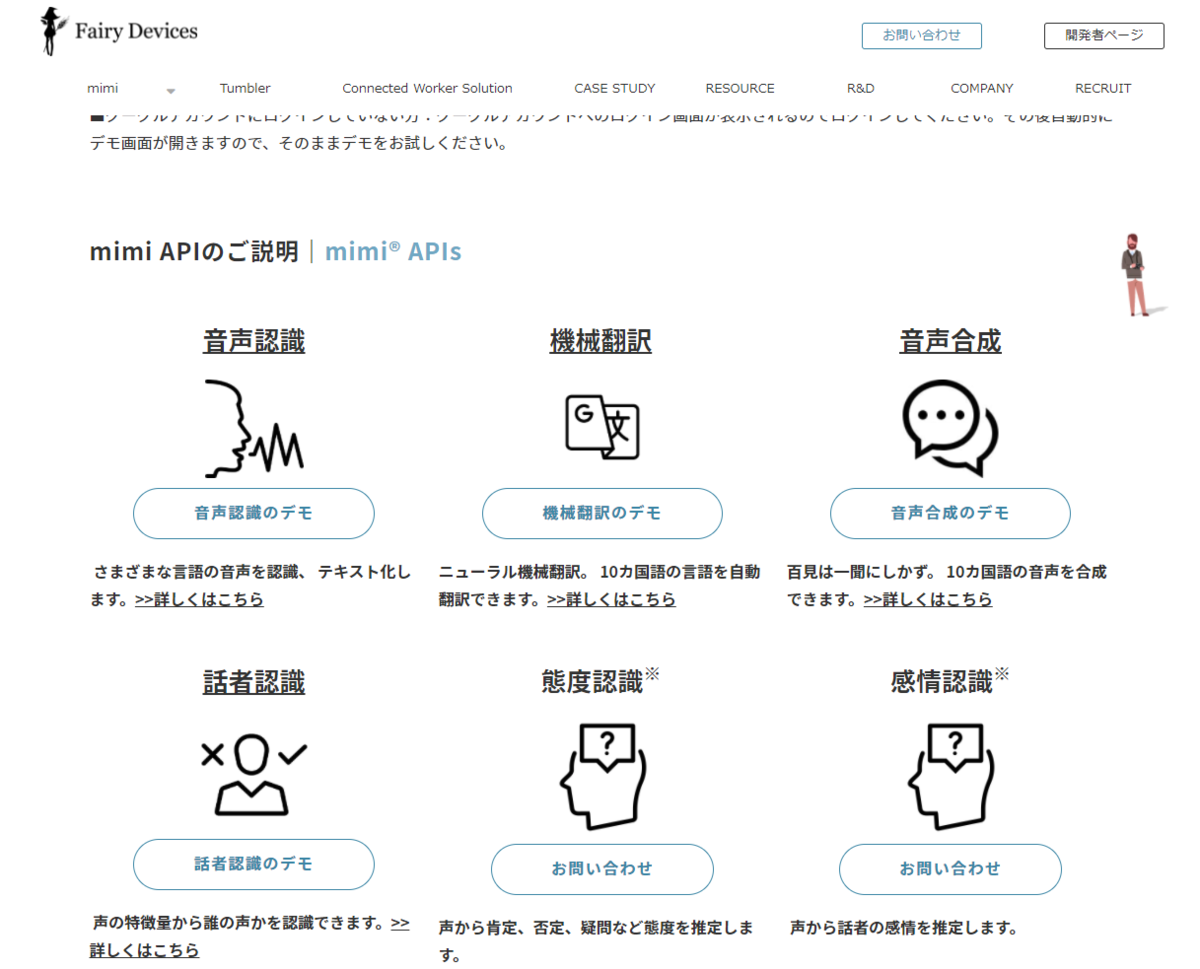

下部はこのようになっていますので、「mimi API console」をクリックすると、ログイン画面が出ます。
そこで、Google アカウントでサインインしてみました。
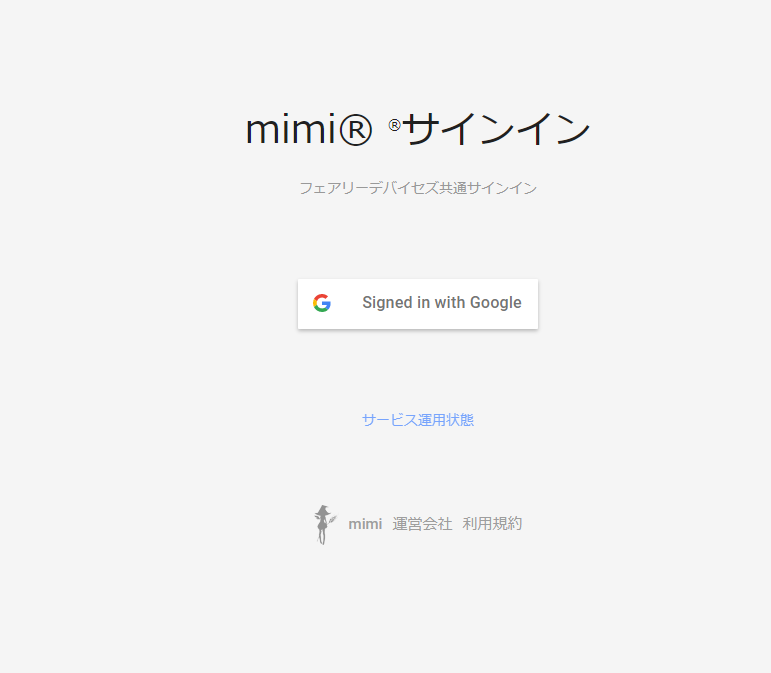
すると、コンソール画面が開きます。
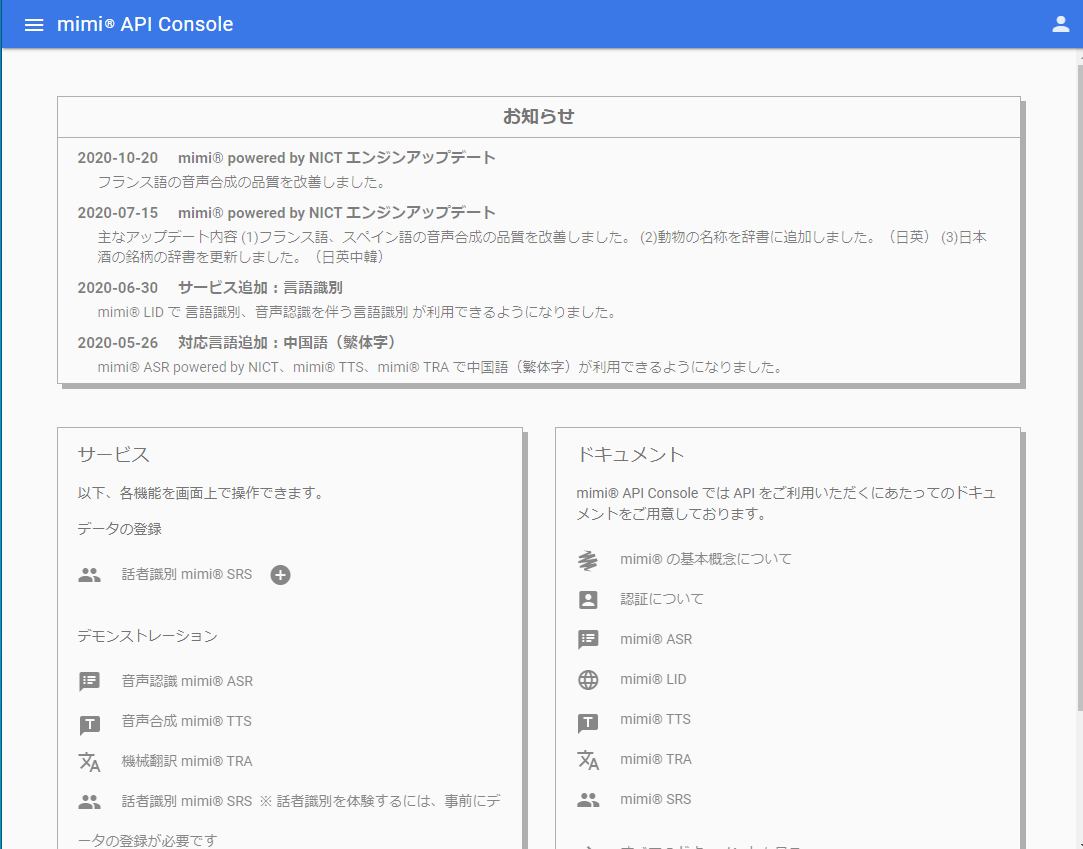
アプリケーションIDおよびクライアントIDの発行
コンソール画面の左上のメニューからアプリケーションを選択します。
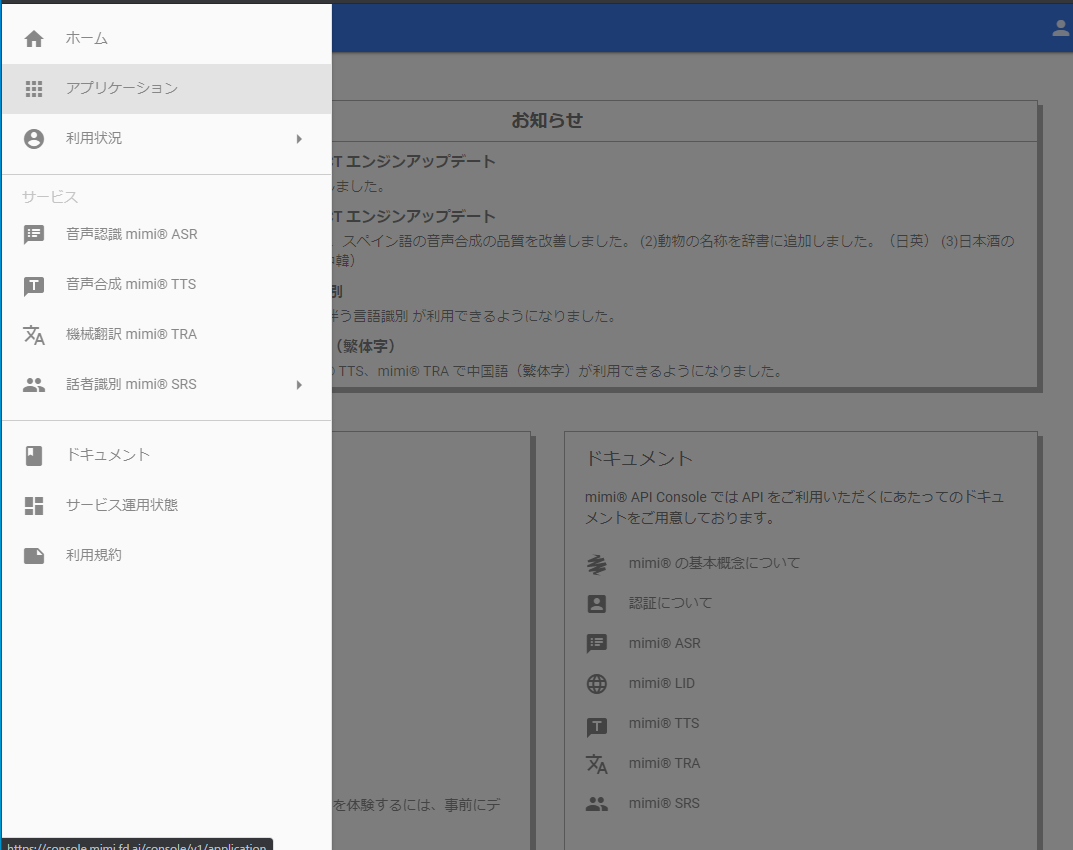
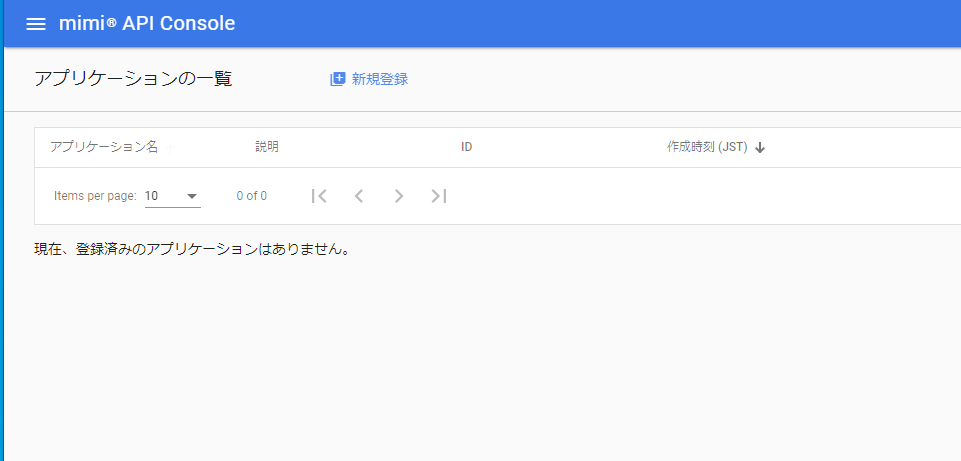
新規登録によってアプリケーションを登録していきます。
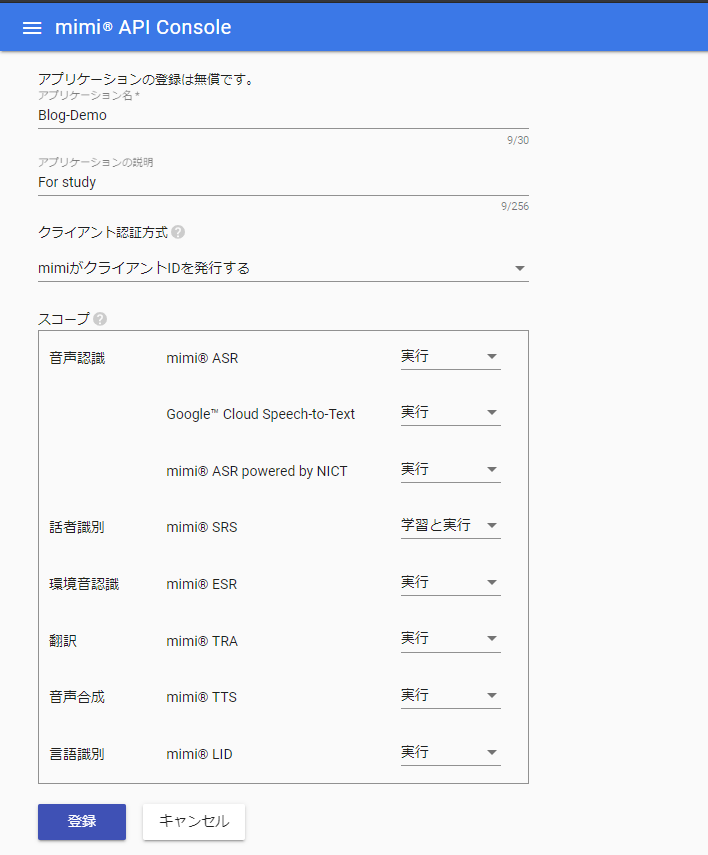
アプリケーション名とDiscriptionを記入したら「登録」しましょう。
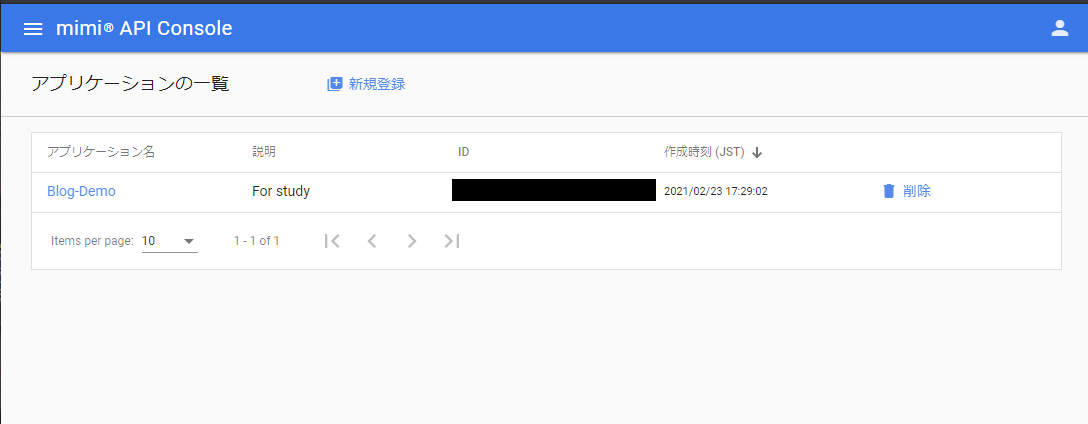
アプリケーションが出来たら、コンソール画面上で、いま登録したアプリをクリックしてみましょう。
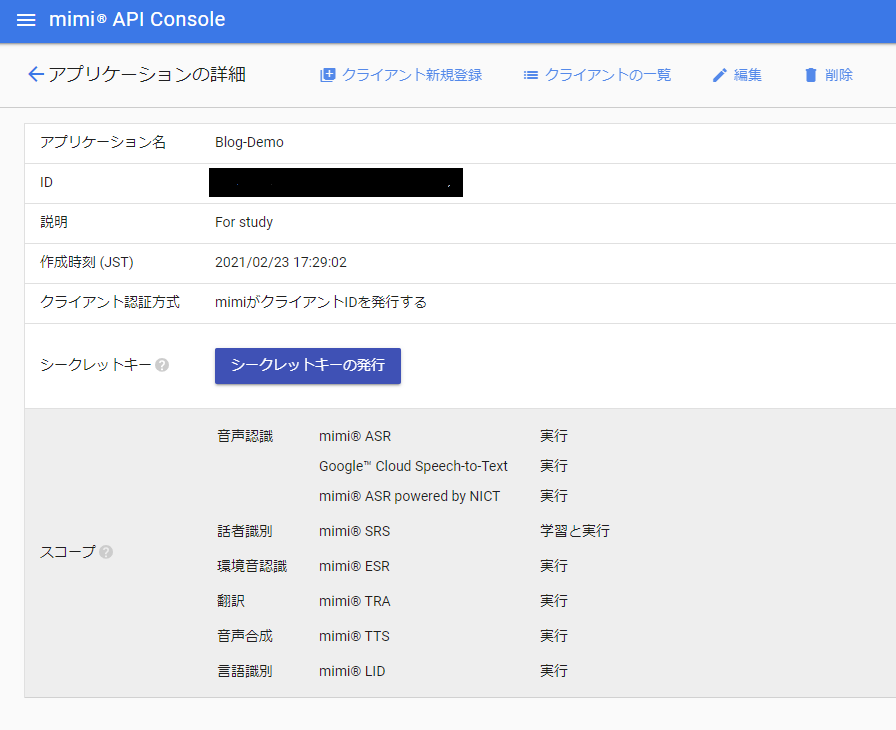
「クライアントの登録」をクリックして、クライアントの登録をします。
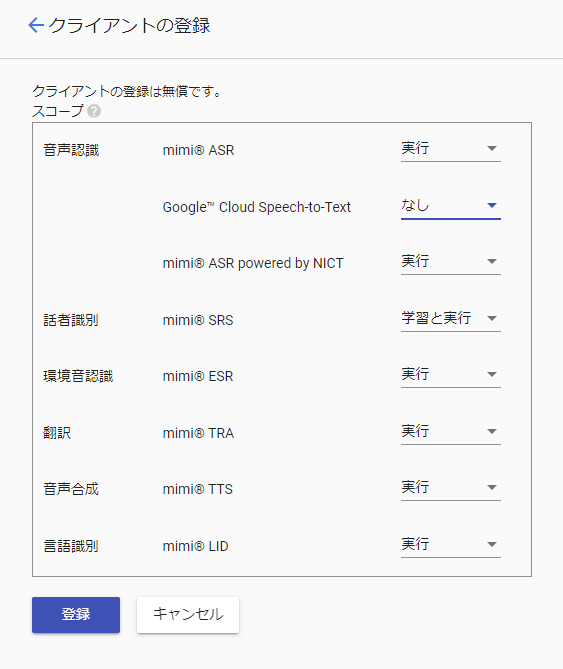
クライアントIDが発行されました。
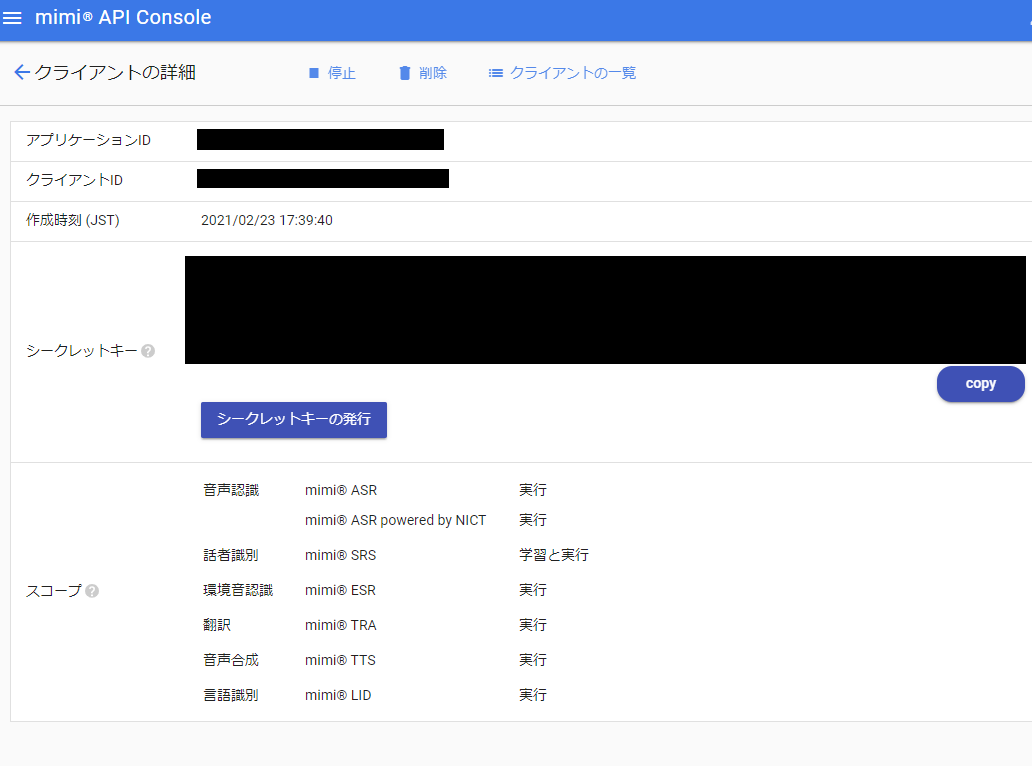
これで、「アプリケーションID」「クライアントID」及び「シークレットキー」の発行が完了しました。
アクセストークンの取得
アクセストークンを取得するために、フォームパラメータを設定していきます。
Google Colaboratryで、アカウント情報を記載します。
cli_id = '<アプリケーションID>:<クライアントID>' cli_secret = '<クライアントシークレット>'
次のパラメータは必須となっています。
- client_id
- client_secret
- scope
- grant_type
これらを設定し、トークンを取得します。
詳しくは、こちらをご覧ください(https://mimi.readme.io/docs/firststep-auth)
import requests url = "https://auth.mimi.fd.ai/v2/token" payload = { 'client_id': cli_id, 'client_secret': cli_secret, 'grant_type': 'https://auth.mimi.fd.ai/grant_type/client_credentials', 'scope': 'https://apis.mimi.fd.ai/auth/asr/websocket-api-service;https://apis.mimi.fd.ai/auth/asr/http-api-service;https://apis.mimi.fd.ai/auth/nict-asr/websocket-api-service;https://apis.mimi.fd.ai/auth/nict-asr/http-api-service;https://apis.mimi.fd.ai/auth/nict-tts/http-api-service;https://apis.mimi.fd.ai/auth/nict-tra/http-api-service', } resp = requests.post(url, data=payload) if resp.status_code == 200: token = resp.json()['accessToken'] else: token = '' token
音声認識を試す
音声ファイルを取得してきます。今回は、サンプルファイルを使用しました。
data = requests.get('https://github.com/FairyDevicesRD/libmimiio/raw/master/examples/audio.raw').content
mimi🄬 ASR 版
headers = {
'Authorization': 'Bearer {}'.format(token),
'Content-Type': 'audio/x-pcm;bit=16;rate=16000;channels=1',
'x-mimi-input-language': 'ja',
'x-mimi-process': 'asr',
}
url = 'https://service.mimi.fd.ai/'
resp = requests.post(url, headers=headers, data=data)
resp.json()

mimi🄬 ASR powerd by NICT版
headers = {
'Authorization': 'Bearer {}'.format(token),
'Content-Type': 'audio/x-pcm;bit=16;rate=16000;channels=1',
'x-mimi-input-language': 'ja',
'x-mimi-process': 'nict-asr',
}
url = 'https://service.mimi.fd.ai/'
resp = requests.post(url, headers=headers, data=data)
resp.json()

音声認識では、2ケースとも「とりあえず」と「腹ごしらえ」を認識しました。
機械翻訳を試す
機械翻訳では、「入力言語」と「テキスト」、「出力言語(翻訳対象の言語)」を指定して、HTTPのrequestsでpostします。
headers = {
'Authorization': 'Bearer {}'.format(token),
}
data = {
'source_lang': 'ja',
'target_lang': 'en',
'text': "ちょっと遅い昼食をとるためファミリーレストランに入ったのです。",
}
url = 'https://tra.mimi.fd.ai/machine_translation'
resp = requests.post(url, headers=headers, data=data)
resp.json()

今回は、Textをダイレクトに入力しましたが、音声認識と併せると、音声入力したデータを翻訳することができます。
音声合成を試す
音声合成は、入力言語及びテキストを指定し、HTTP request でpostします。
headers = {
'Authorization': 'Bearer {}'.format(token),
}
data = {
'lang': 'ja',
'engine': 'nict',
'text': 'ちょっと遅い昼食をとるためファミリーレストランに入ったのです。',
}
url = 'https://tts.mimi.fd.ai/speech_synthesis'
resp = requests.post(url, headers=headers, data=data)
if resp.status_code == 200:
with open('resp.wav', 'wb') as fout:
fout.write(resp.content)
"speech synthesis succeeded."
else:
resp.json()
from IPython.display import Audio
Audio('resp.wav')

結果は、入力したテキストを合成した音声データで読み上げてくれました。(音声データに変換されました)
音としては、「棒読みちゃん」みたいな感じでした。
今回は、mimiというサービスをAPIで繋いで音声に関するDeep Learningモデルで、入出力をしてみました。
次回もお楽しみに!
ではでは。
