【医療画像AI】CNNで医療画像を分類してみた(その1)#002
こんにちは!こーたろーです。
本日は、CNNを使って医療画像の分類をやってみました。
難易度は初級です。
前回はDICOMデータを使い、大変な思いをしましたが、今回はpng形式の画像データなので、少し楽になります。
データのダウンロードから、CNN構築・評価まで行っていきます。
今回のメインは、CNNを利用した4つの方向に回転している胸部CT画像の方向を分類するニューラルネットワークを構築していきます。
これは、4つの方向の他クラス分類に相当します。
以下、内容になります。
- 必要データのダウンロード
- ライブラリ・オブジェクトのインポート
- データのロード及びCNNに入力するためのデータ前処理1(正解ラベル以外)
- CNNに入力するためのデータ前処理2(正解ラベル)
- モデルの構築
- モデルの学習
- モデルの評価
必要データのダウンロード
今回は、画像の向きを検出するCNNを作成していきます。
サンプルデータが日本放射線技術学会 画像部会のページからダウンロードできます。
http://imgcom.jsrt.or.jp/imgcom/wp-content/uploads/2018/12/Directions01_RGB.zip
こちらのリンクを開くと、ダウンロードが開始します。
「Directions01_RGB.zip」という、ファイルがダウンロードされたら、解凍してください。
「train」を今回は使いますので、解凍後は、分かりやすい場所に置いてください。
「train」だけというのも、学習したモデルを評価するときに、今回は「train」のデータでの精度を確認するためです。
次回「test」の方をやろうかと思います。
「train」フォルダの中には、画像の向き毎にフォルダわけがされており、そこから画像を実際に読み取っていきます。
ライブラリ・オブジェクトのインポート
今回のソースコードでは、pythonファイルと同様の階層に「train」のフォルダを配置したケースで記載します。
本ソースコードを使われる場合は、ファイルの参照するパスを、ご自身の「train」フォルダのパスへ設定し直してみてください。
import matplotlib.pyplot as plt import numpy as np import os from os import listdir from keras.preprocessing.image import load_img, img_to_array from tensorflow.python.keras.utils import to_categorical from sklearn.metrics import accuracy_score, confusion_matrix from tensorflow.python.keras.models import Sequential from tensorflow.python.keras.layers import Conv2D, MaxPooling2D, Dropout, Flatten, Dense
データのロード及びCNNに入力するためのデータ前処理1(正解ラベル以外)
次に、CNNの入力データを作成していきます。説明変数に当たる部分ですので、正解ラベル以外のところになります。
32(ピクセル)×32(ピクセル)×3チャネル(RGB)の画像になります。
手順としては、
- フォルダにある画像のファイル名を取得する
- ファイルをTensorflowで利用できる4次元にするための箱を準備する
- 4次元のうち、「横(幅)」「縦(高さ)」の情報を取り出し、4次元の配列に追加する(この時、画素数の正規化をしておく)
- 4つのフォルダの4次元配列を結合して、一つの配列にする
といった手順です。
FnameUp = [filename for filename in listdir('./train/Up') if not filename.startswith('.')] trainU = np.zeros((len(FnameUp),32, 32, 3)) for i in range(0, len(FnameUp)): fnameform = './train/Up/%s' %FnameUp[i] trainU[i] = np.array(img_to_array(load_img(fnameform, target_size=(32,32))))/255.0 FnameDown = [filename for filename in listdir('./train/Down') if not filename.startswith('.')] trainD = np.zeros((len(FnameDown),32, 32, 3)) for i in range(0, len(FnameDown)): fnameform = './train/Down/%s' %FnameDown[i] trainD[i] = np.array(img_to_array(load_img(fnameform, target_size=(32,32))))/255.0 FnameLeft = [filename for filename in listdir('./train/Left') if not filename.startswith('.')] trainL = np.zeros((len(FnameLeft),32, 32, 3)) for i in range(0, len(FnameLeft)): fnameform = './train/Left/%s' %FnameLeft[i] trainL[i] = np.array(img_to_array(load_img(fnameform, target_size=(32,32))))/255.0 FnameRight = [filename for filename in listdir('./train/Right') if not filename.startswith('.')] trainR = np.zeros((len(FnameRight),32, 32, 3)) for i in range(0, len(FnameRight)): fnameform = './train/Right/%s' %FnameRight[i] trainR[i] = np.array(img_to_array(load_img(fnameform, target_size=(32,32))))/255.0 train_all = np.concatenate((trainU, trainD, trainL, trainR), axis=0)
CNNに入力するためのデータ前処理2(正解ラベル)
次に、正解ラベルを作成していきます。
正解ラベルは、フォルダ毎にUP・Down・Left・Rightのラベルを割り当てます。
それぞれ「0」「1」「2」「3」と名付けます。
そして、そのnumpyリストを作成したあとで、4つのリストを結合します。
それらは、One-hotベクトル化することで、CNNの正解ラベルとすることができます。
labelUp = np.full((len(FnameUp), 1), 0, dtype="uint8") labelDown = np.full((len(FnameDown), 1), 1, dtype="uint8") labelLeft = np.full((len(FnameLeft), 1), 2, dtype="uint8") labelRight = np.full((len(FnameRight), 1), 3, dtype="uint8") label_train_All= np.concatenate((labelUp, labelDown, labelLeft, labelRight), axis=0) Onehot_label_All = to_categorical(label_train_All, 4)
モデルの構築
モデルの構築では、目的変数となる画像のデータ(幅、高さ、チャネル)データから、特徴を抽出し、出力を正解ラベルと比較しながら、ネットワークの重みを更新することで、学習を進めていく。
ベースとして使用するのはCNNとなる。前半の特徴抽出では、CNNの基本構成で作成している。
#特徴抽出
model = Sequential() model.add(Conv2D(filters = 32,input_shape = (32, 32, 3),kernel_size = (3, 3), strides = (1, 1),padding = 'same',activation = 'relu')) model.add(Conv2D(filters = 32, kernel_size =(3, 3), strides = (1, 1),padding = 'same',activation = 'relu')) model.add(MaxPooling2D(pool_size =(2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(filters = 64,kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu')) model.add(Conv2D(filters = 64, kernel_size =(3, 3), strides =(1, 1), padding = 'same', activation = 'relu')) model.add(MaxPooling2D(pool_size =(2, 2))) model.add(Dropout(0.25))
上記で特徴を抽出する箇所を作成し、続いて特徴を判別するレイヤーを追加する。
#特徴判別
model.add(Flatten()) model.add(Dense(units=512, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(units= 4, activation='softmax'))
モデルができたら、コンパイルを実施し、実際の構成を確認する。
ここで、「loss='sparse_categorical_crossentropy'」となっていること注意されたい。「loss='categorical_crossentropy' 」とすることも考えられるが、こちらintの扱い条件によりエラーとなる場合がある。
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',metrics=['accuracy']) model.summary()

モデルの学習
モデルの構築が終わったら、モデルの学習を実施する。
model.fitから、画像データである「train_all」及び正解ラベルである「label_train_All」を流していく。
今回は、32ピクセルのキリのいいところでバッチサイズを設定し、エポック数としては10回行う。
また、バリデーションは20%として、検証していく。
model_history = model.fit(train_all,label_train_All,
batch_size = 32,epochs = 10,
validation_split = 0.2)
結果は次のようになった。概ね、ロスがなくなり、正解はほぼ1となっていることが分かる。

モデルの評価
次に、モデルの評価を行っていく。
モデルの評価では、再代入法を使って、トレーニングに使ったデータ「train_all」に対しての正答率を検証する。
probs = model.predict(train_all)
probsには、4つの項目(出力ラベル「0」「1」「2」「3」)における確率が返ってくる。
そこで、confusion_matrixを使って混合行列を作成していく。
results = list(model.predict_classes(train_all, verbose=1)) cmatrix = confusion_matrix(label_train_All, results) cmatrix
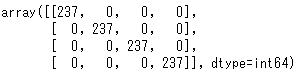
最後に、正解ラベルとの比較を行う。
score = accuracy_score(label_train_All, results) score
![]()
今回の結果では、テストデータを学習させることで、テストデータに対しては100%、分類ができていることが分かる。
今回ダウンロードしたデータは、「Train」と「test」があるため、次回「test」データを使用して、モデルの評価を行っていきます。
ではでは。
