【医療画像AI】CNNで医療画像を分類してみた(その2)#003
こんにちは!こーたろーです。
本日は、CNNを使って医療画像の分類のその2です。
今回の分類は、前回のブログの続きとなりますので、このブログからご覧のかたは、一つ前のブログを一度参照してから、コードを作成してみてください。
CNNで医療画像を分類してみた(その1)【医療画像AI】#002 - 福岡人データサイエンティストの部屋
前回は、評価手法として再代入法による評価でしたが、今回は実際に「Test」データでの評価を行っていきます。
- 必要データのダウンロード
- ライブラリ・オブジェクトのインポート
- 「test」データの処理その1(画像データ処理)
- 「test」データの処理その1(正解ラベル)
- モデルの構築・学習
- Testデータでの予測と評価
必要データのダウンロード
前回同様に日本放射線技術学会 画像部会のページからtestデータをダウンロードします。
http://imgcom.jsrt.or.jp/imgcom/wp-content/uploads/2018/12/Directions01_RGB.zip
こちらのリンクを開くと、ダウンロードが開始します。
前回、ダウンロードした方は再ダウンロードは不要です。
「Directions01_RGB.zip」という、ファイルがダウンロードされたら、解凍してください。
前回は「train」のフォルダを使って学習させました。今回は、「train」のフォルダで学習させたモデルに「test」データを入れて評価します。
ライブラリ・オブジェクトのインポート
「test」のフォルダは、pythonファイルと同じ階層に配置しております。
本ソースコードを使われる場合は、ファイルの参照するパスを、ご自身の「train」フォルダのパスへ設定し直してみてください。
import matplotlib.pyplot as plt import numpy as np import os from os import listdir from keras.preprocessing.image import load_img, img_to_array from tensorflow.python.keras.utils import to_categorical from sklearn.metrics import accuracy_score, confusion_matrix from tensorflow.python.keras.models import Sequential from tensorflow.python.keras.layers import Conv2D, MaxPooling2D, Dropout, Flatten, Dense
ライブラリ・オブジェクトのインポートは前回と同じでやっていきます。
前回の続きからpythonファイル編集するといいかもしれません。(実際にそうやって書いています)
「test」データの処理その1(画像データ処理)
Test用の画像についても32(ピクセル)×32(ピクセル)×3チャネル(RGB)の画像になります。
前回のTrainデータの処理と同様の処理をTestデータに対しても行っていきます。
手順としては、
- フォルダにある画像のファイル名を取得する
- ファイルをTensorflowで利用できる4次元にするための箱を準備する
- 4次元のうち、「横(幅)」「縦(高さ)」の情報を取り出し、4次元の配列に追加する(この時、画素数の正規化をしておく)
- 4つのフォルダの4次元配列を結合して、一つの配列にする
といった手順です。
FnameUp = [filename for filename in listdir('./test/Up') if not filename.startswith('.')] testU = np.zeros((len(FnameUp),32, 32, 3)) for i in range(0, len(FnameUp)): fnameform = './test/Up/%s' %FnameUp[i] testU[i] = np.array(img_to_array(load_img(fnameform, target_size=(32,32))))/255.0 FnameDown = [filename for filename in listdir('./test/Down') if not filename.startswith('.')] testD = np.zeros((len(FnameDown),32, 32, 3)) for i in range(0, len(FnameDown)): fnameform = './test/Down/%s' %FnameDown[i] testD[i] = np.array(img_to_array(load_img(fnameform, target_size=(32,32))))/255.0 FnameLeft = [filename for filename in listdir('./test/Left') if not filename.startswith('.')] testL = np.zeros((len(FnameLeft),32, 32, 3)) for i in range(0, len(FnameLeft)): fnameform = './test/Left/%s' %FnameLeft[i] testL[i] = np.array(img_to_array(load_img(fnameform, target_size=(32,32))))/255.0 FnameRight = [filename for filename in listdir('./test/Right') if not filename.startswith('.')] testR = np.zeros((len(FnameRight),32, 32, 3)) for i in range(0, len(FnameRight)): fnameform = './test/Right/%s' %FnameRight[i] testR[i] = np.array(img_to_array(load_img(fnameform, target_size=(32,32))))/255.0 test_all = np.concatenate((testU, testD, testL, testR), axis=0) test_all.shape
「test」データの処理その1(正解ラベル)
次に、正解ラベルを作成していきます。
正解ラベルは、フォルダ毎にUP・Down・Left・Rightのラベルを割り当てます。
それぞれ「0」「1」「2」「3」と名付けます。
そして、そのnumpyリストを作成したあとで、4つのリストを結合します。
それらは、One-hotベクトル化することで、CNNの正解ラベルとすることができます。
labelUp = np.full((len(FnameUp), 1), 0, dtype="uint8") labelDown = np.full((len(FnameDown), 1), 1, dtype="uint8") labelLeft = np.full((len(FnameLeft), 1), 2, dtype="uint8") labelRight = np.full((len(FnameRight), 1), 3, dtype="uint8") label_test_All= np.concatenate((labelUp, labelDown, labelLeft, labelRight), axis=0) Onehot_label_All = to_categorical(label_test_All, 4)
モデルの構築・学習
前回のブログで学習させたモデルを使うため、今回は省略です。確認はこちらから。
CNNで医療画像を分類してみた(その1)【医療画像AI】#002 - 福岡人データサイエンティストの部屋
Testデータでの予測と評価
作成したテストデータを投入していきます。また、正解ラベルについても混合行列に入れて評価していきます。
probs = model.predict(test_all) results = list(model.predict_classes(test_all, verbose=1)) cmatrix = confusion_matrix(label_test_All, results) cmatrix
混合行列はこのようになりました。
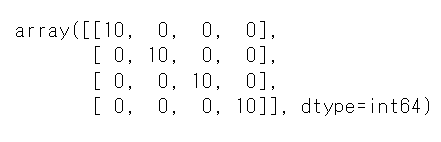
最後に、正解率を確認します。
score = accuracy_score(label_test_All, results) score
![]()
テストデータは、各10枚ずつしかないですが、作成したCNNは十分に画像の向きを判別できるレベルになっていることが分かります。
この処理が、どのように役に立つかというと、データストレージの管理で訳に立ちます。
これらの医療画像が大量に集まっているデータレイクを考えると、いちいち向きを確認して、揃えることは大変な労力が必要になってきます。
そこで、データレイクからDWH(データウエアハウス)へ移行するときにこのような機械学習がもちられることがあります。
単純な作業ではありますが、画像の向きを判定するAIを作成し、全ての画像をUPの方向にする処理を加えることで、DWHでは向きの揃った画像になりますね。
データサイエンティストとしては、ストレージ管理も重要なので、こういったAIも役立つと思っています。
ではでは。
