【SVM】手書き文字識別やってみた【Python】
こんにちは!こーたろーです。
ちょっとブログにつかれてきたので、基礎トレーニングも混ぜながらやっていきます。
1年前に少しやりましたが、今回は別のモデルでやってみます。
手書き文字識別をSVM(サポートベクターマシン)を使ってやってみます。
学生の練習にはうってつけですね。
データのロード
データは、UCIのデータになります。
UCI Machine Learning Repository
scikit-learn から呼び出せるため、それを使ていきます。
from sklearn import datasets text = datasets.load_digits() print(text.DESCR)
Descriptionを表示させるとこんな感じです。

データの数が1797枚(画像の枚数)、8×8(64)ピクセルのようです。
データの取り出し方としては、
[変数].images : 画像の情報
[変数].target : 正解ラベル
で取り出すことができます。
画像を少し見てみます。
import matplotlib.pyplot as plt for i in range (9): plt.subplot(3, 3, i+1) plt.title(str(text.target[i])) plt.imshow(text.images[i], cmap = "gray") plt.show()
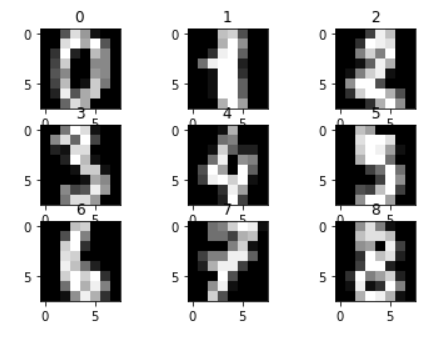
64ピクセルなだけあって、結構粗いことが分かります。
データの前処理
データは、既にできているので、機械学習できるように加工します。
from sklearn.model_selection import train_test_split x = text.images y = text.target x = x.reshape((-1, 64)) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2)
各イメージ画像のデータをxに、正解ラベルをyに取り出します。
xラベルについては、機械学習のために、8×8の2次元になっているところを64の1次元に変換しておきます。
そして、学習データとテストデータに分けます。
モデルの作成と学習、評価
モデルの作成と学習、評価を行います。
from sklearn import datasets, svm, metrics from sklearn.metrics import accuracy_score model = svm.LinearSVC() model.fit(x_train, y_train) y_pred = model.predict(x_test) accuracy_score(y_test, y_pred)
SVMの中の線形分類を行うSVCをつかって行います。
![]()
正答率としては、94%で識字できています。
64ビットで、これだけでれば十分かなと思います。
予測値と正解値をマトリックスで表示してみます。
import numpy as np import pandas as pd y_test = np.array(y_test) y_pred = np.array(y_pred) matrix = np.array([y_test,y_pred]).T df = pd.DataFrame(matrix, columns = ["y_test","y_pred"] ) df
ごちゃごちゃしていますが、見やすいようにDataFrameで縦に並べてみました。

画像で見えている範囲は、全て正解していますね。
360データのうち、339個が正解のようです。
皆さんもやってみてください。
ではでは。
サポートベクターマシン入門