亡くなった人をチャットボットに???【コラム】#004
こんにちは!こーたろーです。
先日こんな記事を見かけました。
【マイクロソフト、亡くなった人をチャットボットにできる特許を取得 | ギズモード・ジャパン】
とうやら、マイクロソフトの方で、アメリカの特許商標庁に提出された特許では、亡くなった人の画像や音声データ、SNSへの投稿、電子メッセージなどの情報からチャットボットを作成するというものが公開されている。
これを見たとき、まず思い出したのは、葬儀の時の遺影の表情が変化するサービス。
【進化する日本の葬儀業、ついに遺影が・・・動き出す!=中国メディア (2019年12月9日) - エキサイトニュース 】
故人情報が後世に残って、あたかも生きているときのようにふるまうという発想。
これは、昔見たアニメ攻殻機動隊のように、電脳化の世界へ向けて前進したような気がするのは私だけでしょうか。
AIもシンギュラリティを迎え、さらに進化を遂げていくと、意思を持ち始めるといったことが可能になるかもしれません。
電脳化して生き続ける世界。皆さんはどう思いますか?
攻殻機動隊を見ながらいろいろ考えさせられることもあったなーと懐かしく思っています。
ネットの世界で生き続けるというのは、どういった感情になるのか。。。
GHOSTがささやくのか!?!?
ではでは。
![GHOST IN THE SHELL/攻殻機動隊 [Blu-ray]](https://m.media-amazon.com/images/I/51zQhaRZOLL.jpg "GHOST IN THE SHELL/攻殻機動隊 [Blu-ray]")
![攻殻機動隊 Stand Alone Complex 1st & 2nd Gig [import][DVD][PAL]](https://m.media-amazon.com/images/I/511WXqgJuKL.jpg "攻殻機動隊 Stand Alone Complex 1st & 2nd Gig [import][DVD][PAL]")
学習済みGAN使ってみた【図解速習Deep Learning】#009
こんにちは!こーたろーです。
本日はついにGANに取り掛かっていきます。
今日はdemoですが(笑
本日も【図解速習DEEP LEARNING】をやっていきます。
皆さんもう買いました? すべてを理解するのは結構難しいですよね。。汗
それでは早速本日分!
サンプルコードではTensorFlow1.Xですが、今回もTensorFlow2.4.0でやっていきます。
コードが変わっていますのでご注意ください。
この辺のバグ取りなんかは、Python、TensorFlowの勉強になって、とても為になっています。
GANをやっていきますが、今回は学習済みのGANのコレクションを使って、画像生成を行います。
洗剤空間上のランダムなベクトルを選び、それをGANへ入力し、画像を生成するという流れです。
ではソースコードを見ていきましょう。
1.ライブラリのインポート
from google.colab import output import matplotlib.pyplot as plt import numpy as np import pandas as pd import tensorflow as tf import tensorflow_hub as hub tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)
2.モデルを取得
辞書型で入れているGANモデルを選択すると、Tensorflow_hubからモデルをダウンロードします。
module_metadata_dict = {'dataset': ['CelebA HQ (128x128)', 'CelebA HQ (128x128)', 'LSUN Bedroom', 'LSUN Bedroom', 'CelebA HQ (128x128)', 'CelebA HQ (128x128)', 'LSUN Bedroom', 'LSUN Bedroom', 'CelebA HQ (128x128)', 'LSUN Bedroom', 'CIFAR10', 'CIFAR10', 'CIFAR10', 'CIFAR10', 'CIFAR10'], 'penalty': ['-', '-', '-', '-', '-', '-', '-', '-', 'DRAGAN (lambda=1.000)', 'WGAN (lambda=0.145)', '-', '-', '-', '-', 'WGAN (lambda=1.000)'], 'architecture': ['ResNet19', 'ResNet19', 'ResNet19', 'ResNet19', 'ResNet19', 'ResNet19', 'ResNet19', 'ResNet19', 'ResNet19', 'ResNet19', 'ResNet CIFAR', 'ResNet CIFAR', 'ResNet CIFAR', 'ResNet CIFAR', 'ResNet CIFAR'], 'beta1': ['0.375', '0.500', '0.585', '0.195', '0.500', '0.500', '0.500', '0.102', '0.500', '0.711', '0.500', '0.500', '0.500', '0.500', '0.500'], 'beta2': ['0.998', '0.999', '0.990', '0.882', '0.999', '0.999', '0.999', '0.998', '0.900', '0.979', '0.999', '0.999', '0.999', '0.999', '0.999'], 'module_url': ['https://tfhub.dev/google/compare_gan/model_1_celebahq128_resnet19/1', 'https://tfhub.dev/google/compare_gan/model_2_celebahq128_resnet19/1', 'https://tfhub.dev/google/compare_gan/model_3_lsun_bedroom_resnet19/1', 'https://tfhub.dev/google/compare_gan/model_4_lsun_bedroom_resnet19/1', 'https://tfhub.dev/google/compare_gan/model_5_celebahq128_resnet19/1', 'https://tfhub.dev/google/compare_gan/model_6_celebahq128_resnet19/1', 'https://tfhub.dev/google/compare_gan/model_7_lsun_bedroom_resnet19/1', 'https://tfhub.dev/google/compare_gan/model_8_lsun_bedroom_resnet19/1', 'https://tfhub.dev/google/compare_gan/model_9_celebahq128_resnet19/1', 'https://tfhub.dev/google/compare_gan/model_10_lsun_bedroom_resnet19/1', 'https://tfhub.dev/google/compare_gan/model_11_cifar10_resnet_cifar/1', 'https://tfhub.dev/google/compare_gan/model_12_cifar10_resnet_cifar/1', 'https://tfhub.dev/google/compare_gan/model_13_cifar10_resnet_cifar/1', 'https://tfhub.dev/google/compare_gan/model_14_cifar10_resnet_cifar/1', 'https://tfhub.dev/google/compare_gan/model_15_cifar10_resnet_cifar/1'], 'disc_iters': [1, 1, 1, 1, 1, 1, 1, 1, 5, 1, 5, 5, 5, 5, 5], 'model': ['Non-saturating GAN', 'Non-saturating GAN', 'Least-squares GAN', 'Non-saturating GAN', 'Non-saturating GAN', 'Non-saturating GAN', 'Least-squares GAN', 'Non-saturating GAN', 'Non-saturating GAN', 'Non-saturating GAN', 'Non-saturating GAN', 'Non-saturating GAN', 'Non-saturating GAN', 'Non-saturating GAN', 'Non-saturating GAN'], 'inception_score': ['2.38', '2.59', '4.23', '4.10', '2.38', '2.54', '3.64', '3.58', '2.34', '3.92', '7.57', '7.47', '7.74', '7.74', '7.70'], 'disc_norm': ['none', 'none', 'none', 'none', 'layer_norm', 'layer_norm', 'spectral_norm', 'spectral_norm', 'layer_norm', 'layer_norm', 'none', 'none', 'spectral_norm', 'spectral_norm', 'spectral_norm'], 'fid': ['34.29', '35.85', '102.74', '112.92', '30.02', '32.05', '41.60', '42.51', '29.13', '40.36', '28.12', '30.08', '22.91', '23.22', '22.73'], 'ms_ssim_score': ['0.32', '0.29', 'N/A', 'N/A', '0.29', '0.28', 'N/A', 'N/A', '0.30', 'N/A', 'N/A', 'N/A', 'N/A', 'N/A', 'N/A'], 'learning_rate': ['3.381e-05', '1.000e-04', '3.220e-05', '1.927e-05', '1.000e-04', '1.000e-04', '2.000e-04', '2.851e-04', '1.000e-04', '1.281e-04', '2.000e-04', '1.000e-04', '2.000e-04', '2.000e-04', '2.000e-04']}
MODULE_METADATA = pd.DataFrame.from_dict(module_metadata_dict)
MIN_FID_MODULE = MODULE_METADATA.loc[
MODULE_METADATA['fid'].astype(float).idxmin()]
SELECTED_MODULE = MIN_FID_MODULE['module_url']
SELECTED_MODULE_DATASET = MIN_FID_MODULE['dataset']
def display_images(images, captions=None):
batch_size, dim1, dim2, channels = images.shape
num_horizontally = 8
figsize = (20, 20) if dim1 > 32 else (10, 10)
f, axes = plt.subplots(
len(images) // num_horizontally, num_horizontally, figsize=figsize)
for i in range(len(images)):
axes[i // num_horizontally, i % num_horizontally].axis("off")
if captions is not None:
axes[i // num_horizontally, i % num_horizontally].text(0, -3, captions[i])
axes[i // num_horizontally, i % num_horizontally].imshow(images[i])
f.tight_layout()
class ShowModuleTable(object):
def __init__(self, callback):
self._callback = callback
def _repr_html_(self):
template = """
<style>
table {
font-size: 15px;
font-family: Inconsolata, monospace;
border-collapse: collapse;
border: 1px solid #444444;
}
th {
font-size: 18px;
background-color: #DDDDDD;
border: 1px solid #AAAAAA;
white-space: nowrap;
}
tr {
cursor: pointer;
white-space: nowrap;
}
td {
padding: 6px 6px 6px 6px;
border: 1px solid #AAAAAA;
}
.selected-row {
font-weight: bold;
background-color: #B0BED9;
}
</style>
<table>"""
table_headers = [
('dataset', 'Dataset'),
('architecture', 'Architecture'),
('fid', 'FID'),
('inception_score', 'IS'),
('ms_ssim_score', 'MS-SSIM'),
('model', 'Model'),
('learning_rate', 'Learning rate'),
('beta1', 'β<sub>1</sub>'),
('beta2', 'β<sub>2</sub>'),
('disc_iters', 'n<sub>disc</sub>'),
('disc_norm', 'Disc norm'),
('penalty', 'Penalty'),
('module_url', 'Module name'),
]
header_template = "<tr>"
for _, header_name in table_headers:
header_template += "<th>" + header_name + "</th>"
header_template += "</tr>"
template += header_template
for i, (_, row) in enumerate(MODULE_METADATA.iterrows()):
uuid = "row-%s" % i
output.register_callback(uuid, self._callback)
selected_class = ""
if row['module_url'] == MIN_FID_MODULE['module_url']:
selected_class = "class=\"selected-row\""
row_template = "<tr id=\"" + uuid + "\"" + selected_class + ">"
for key, _ in table_headers:
row_template += "<td>" + str(row[key]) + "</td>"
row_template += "</tr>"
template += row_template
template += """
</table>
<script>"""
for i, (_, row) in enumerate(MODULE_METADATA.iterrows()):
uuid = "row-%s" % i
m = row['module_url']
d = row['dataset']
template += """
document.querySelector(\"#""" + uuid + """\").onclick = function() {
google.colab.kernel.invokeFunction('""" + uuid + """', ['""" + m +"""', '""" + d + """'], {});
var selected = document.getElementsByClassName('selected-row');
for (var i = 0; i < selected.length; i++) {
selected[i].classList.remove('selected-row');
}
this.classList.toggle("selected-row");
e.preventDefault();
};
"""
template += """</script>"""
return template
def set_selected_module(module_name, dataset):
global SELECTED_MODULE
SELECTED_MODULE = module_name
global SELECTED_MODULE_DATASET
SELECTED_MODULE_DATASET = dataset
ShowModuleTable(set_selected_module)
一覧表示したらこんな感じです。

下記の「assert」の使い方は覚えておいた方がいいです!
今度解説したいと思います。
assert SELECTED_MODULE is not None and SELECTED_MODULE_DATASET is not None, \ 'You must run the above cell and select a module from the table to generate images.' print('Using module: "%s"' % SELECTED_MODULE) print('Generating images like dataset: "%s"' % SELECTED_MODULE_DATASET) batch_size = 64 z_dim = 128 with tf.Graph().as_default(): gan = hub.Module(SELECTED_MODULE) z_input = tf.compat.v1.placeholder(dtype=tf.float32, shape=(batch_size, z_dim)) image_output = gan(z_input, signature="generator") with tf.compat.v1.train.MonitoredSession() as session: z_values = np.random.uniform(-1, 1, size=(batch_size, z_dim)) images = session.run(image_output, feed_dict={z_input: z_values}) display_images(images)
Z_input という潜在空間ベクトルを定義しています。
そこからGANを使って画像を生成しています。
結果がこちら↓↓↓↓↓

メタデータから別の学習済みGANを選択するには、上記のコードのうち、
MIN_FID_MODULE = MODULE_METADATA.loc[
MODULE_METADATA['fid'].astype(float).idxmin()]
の部分を変更してみてください。
モジュールダイレクト入力なんかでも大丈夫です。
一覧表示のコードの記述が面倒なので、一つずつ使ってみてもいいかもしれませんね。
「Dataset : LSUN Bedroom」、「model : model_4_lsun_bedroom_resnet19」の場合

こんな感じです。
いかがでしたでしょうか。
よくわかりませんよね。。。汗
入力から画像を生成しただけなので、GAN本来の特性が出ていない感じがします。
入門編なのでこんなもんなのかな? GANも後々作成できたらと思っています。
ではでは。
DELF使って特徴くらべてみた【図解速習Deep Learning】#008
こんにちは!こーたろーです。
今日は【図解速習DEEP LEARNING】の続きです!!
実践はどんどん続き、本日は「DELF」を使ってみます。
DELFは、画像を処理し、特徴点とそれらの特徴量記述を識別するロジックです。
説明を忘れていましたが、最近使っていた「Tensorflow Hub」は、事前に学習されたモジュール群を再利用可能なリソースとしてパッケージ化したものです。
学習を済ませているため、学習データを準備する必要がなく、今後活用例などが出てくるかもしれません。
しかし、特徴を抽出するにとどまっているので、そのあとどう処理するかというところは、開発しなければならないです。
それでは始めます。
1.ライブラリのインストール
!pip install -q 'tensorflow-hub' !pip install -q 'scikit-image'
2.ライブラリのインポート
from absl import logging import matplotlib.pyplot as plt import matplotlib.image as mpimg import numpy as np from PIL import Image, ImageOps from scipy.spatial import cKDTree from skimage.feature import plot_matches from skimage.measure import ransac from skimage.transform import AffineTransform from six import BytesIO import tensorflow as tf import tensorflow_hub as hub from six.moves.urllib.request import urlopen
3.比較したい2つの画像のURLを指定
IMAGE_1_URL = 'https://upload.wikimedia.org/wikipedia/commons/d/d8/Eiffel_Tower%2C_November_15%2C_2011.jpg' IMAGE_2_URL = 'https://upload.wikimedia.org/wikipedia/commons/a/a8/Eiffel_Tower_from_immediately_beside_it%2C_Paris_May_2008.jpg'
4.画像のダウンロードを行い、resizeを行う
ダウンロードとresizeを行う関数を定義
def download_and_resize(name, url, new_width=256, new_height=256): path = tf.keras.utils.get_file(url.split('/')[-1], url) image = Image.open(path) image = ImageOps.fit(image, (new_width, new_height), Image.ANTIALIAS) return image
各URLに対して、画像を取得する
image1 = download_and_resize('image_1.jpg', IMAGE_1_URL) image2 = download_and_resize('image_2.jpg', IMAGE_2_URL) plt.subplot(1,2,1) plt.imshow(image1) plt.subplot(1,2,2) plt.imshow(image2)

チュートリアルの中のこちらの画像を使用しました。
5.DELFモジュールのロード
delf = hub.load('https://tfhub.dev/google/delf/1').signatures['default']
6.各イメージにDELFを実行
DELFモジュールは、画像を入力とし、特徴点をベクトル形式で出力します。
DELFを実行するための関数を定義(前処理部分の記述)
def run_delf(image): np_image = np.array(image) float_image = tf.image.convert_image_dtype(np_image, tf.float32) return delf( image=float_image, score_threshold=tf.constant(100.0), image_scales=tf.constant([0.25, 0.3536, 0.5, 0.7071, 1.0, 1.4142, 2.0]), max_feature_num=tf.constant(1000))
各画像に対してDELFを実行
result1 = run_delf(image1) result2 = run_delf(image2)
7.比較結果の描画
def match_images(image1, image2, result1, result2): distance_threshold = 0.8 num_features_1 = result1['locations'].shape[0] print("Loaded image 1's %d features" % num_features_1) num_features_2 = result2['locations'].shape[0] print("Loaded image 2's %d features" % num_features_2) d1_tree = cKDTree(result1['descriptors']) _, indices = d1_tree.query( result2['descriptors'], distance_upper_bound=distance_threshold) locations_2_to_use = np.array([ result2['locations'][i,] for i in range(num_features_2) if indices[i] != num_features_1 ]) locations_1_to_use = np.array([ result1['locations'][indices[i],] for i in range(num_features_2) if indices[i] != num_features_1 ]) _, inliers = ransac( (locations_1_to_use, locations_2_to_use), AffineTransform, min_samples=3, residual_threshold=20, max_trials=1000) print('Found %d inliers' % sum(inliers)) _, ax = plt.subplots() inlier_idxs = np.nonzero(inliers)[0] plot_matches( ax, image1, image2, locations_1_to_use, locations_2_to_use, np.column_stack((inlier_idxs, inlier_idxs)), matches_color='b') ax.axis('off') ax.set_title('DELF correspondences')
match_images(image1, image2, result1, result2)

他のはこんな感じになりました。




どんどん難しくなっている気がしますね。。
Tensorflow極めないと。。。そして、メソッドも覚えないと。。。
勉強することはかなりありそうですね。
ではでは。。
DLフレームワーク「SmallTrain 0.2.1」リリース【コラム】#003
こんにちは!こーたろーです。
Geek Guild社がディープラーニングのフレームワークをオープンソースソフトウェアとしてリリースしたようです。
どうやら学習済みモデルが内包されていて、そのまま活用可能なパッケージがあるとか。
しかも「Jupyter Notebook」対応。
利点は記事にも書いていますが、引用させていただいて、
【利点】
- 最小限のデータサイエンスのバックグラウンドで、PoCだけでなく本運用を見据えた開発が可能 ⇐今度中身をみてみましょう!
- TensorFlowおよびPyTorchラッパーとして利用できる ⇐なるほど!いいね☆
- AI研究論文の先端のアルゴリズムを使用して学習済みモデルを構築している ⇐学習ソースが問題かな?
- 最小限のデータと学習時間で精度が向上 ⇐転移学習が簡単にできるってことかな
- 「SmallTrain」は様々なデータを事前学習している ⇐ 学習済みがあるって素敵💛
- MITライセンスに準拠したオープンソースのため、バグ修正や改善について心配が不要 ⇐MITライセンスの信頼度!!
参考URL(記事) 、出典
ディープラーニングフレームワーク「SmallTrain 0.2.1」がリリース:CodeZine(コードジン)
こういったパッケージが大量にあふれだすと、こちらもどれを使っていいのか・・・ってなりそう。。。(汗
基本はTensorFlow、PyTorch、OpenCVとかそのあたりを使えればいいのかな?
皆さんの意見が聞いてみたいです。
ではでは。。

AIブームから5年。・・・・【コラム】#002
こんにちは!コータローです。
情報発信として、ニュースなどをピックアップして、私の考えを述べるコラムもブログに投稿したいと考えています。
日々情報収集する中から、気になるニュースをチェック!ということで。
本日はこちらです。
ベンチャー企業では、AIブームを捉えて、AIをビジネスに役立てるためにいろいろな思考錯誤が行われているようです。
特に取り掛かりやすい画像認識関連のビジネス。
最近ではパン屋のレジで商品をかざすだけで、どの商品かを見分けて、料金計算をおこなう、といった形で実用化されたケースもニュースでみました。
コロナ禍においては、画像で様々な認識を行っているものもよく目にしますね。
体温もそうですし、マスクの着用の有無など。
この記事では、概念実証(PoC)などをやって受注を受けているが、データのクレンジング業務に追われる企業が多く、本番(中・長期的な契約)までたどり着けていないといったことが記されている。
私が働いていた職場でも、こういったデジタル技術の導入に意欲はみせるけれども、費用対効果がどうなるかといった、経営面の課題や経営陣の説得が難しく、また価格がいくらが妥当かなどの議論をする中で、PoCを超えることができなかったケースが沢山有ります。
記事では、製造業についても書いていますが、AI・データ分析をソリューションとする課題は多くあるものの、活用するためのデータを取得する部分や分析インフラを構築することろに壁がある模様。
工場関係でIoTを行う(IIoT)と呼ばれる技術を導入しなければならないが、センサーやカメラなどの大幅な投資が必要となってくる。
最近ではPoCなどのスモールスタートで、どんどんスケーリングさせていくということは考えられるが、上記に書いたように技術進歩の早さも相まって、一つのソリューションで一気通貫に行うことが難しいのも実際のところのようだ。
ベンチャービジネスは、こういった壁を乗り越えて、導入に漕ぎつけた企業がユニコーンとなる。その難しさは、これまでベンチャー企業を3社経験した私はよく知っている。
コラムでは、自分の経験なども踏まえて、コメントできたらなと思います。
今後ともコラムも宜しくお願いします。
ではでは。

統計の基礎やってみた【やさしく学ぶデータ分析に必要な統計の教科書】#001
こんにちは!こーたろーです。
今日は、統計学の基礎をやってみます。
というのも、データ分析は機械学習や深層学習だけではなく、統計も必要となってくるからです。
実社会では、AI分野を除けば基本的に統計学の方がよく使うのではないか?と勝手に考えて、今回から統計もやることにしました。
教材は【やさしく学ぶ データ分析に必要な統計の教科書 できるビジネスシリーズ】を使用していきます。
こちらは、データ分析をExcelで行っているのですが、これをこのブログではGoogle ColabratoryでPythonを使って行ってみたいと思います!
課題 2-1
データの最大値、最小値を求める。
1.必要なライブラリをインポートする。
import pandas as pd
2.データの読み込み
sample_df = pd.read_csv('2_1.csv' , sep=',')
3.データを確認
sample_df
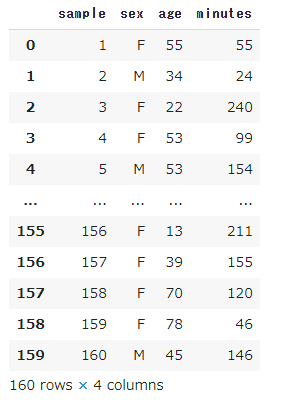
こんな感じです。
性別と年齢情報と1日当たりのインターネット利用時間(分)がデータとして160件入っています。
4.最大、最小値を求めて表示させます。
a = sample_df['minutes'].max() b = sample_df['minutes'].min() print('max is {0}, min is {1}'.format(a,b))

結果は、最大が287分、最小が10分という結果になりました。
こんな感じで、こちらのテキストをpythonで行い、統計を行いながら
Pythonの基礎操作についても学んでいけたらと思います。
次回からはもう少したくさんやります。
ではでは。
データサイエンティスト協会の加入申請だした【コラム】#001
こんにちは!こーたろーです。
本日はプログラミングの日記は休憩して・・・
(毎日更新してたら疲れました。。。orz)
データサイエンティスト協会に申し込んだ話です。
過去の日記でも紹介しましたが、データサイエンティストたるもの情報収集は重要な活動の一つです。
(データサイエンティストやってます【図解速習Deep Learning】 #001 - 福岡の社会人データサイエンティストの部屋)
その中でも、最新の情報を手に入れる方法は多数ありますが、これまで私は以下のような方法をやっていました。
- データサイエンティスト関連のニュースの閲覧
- Facebookのデータサイエンス関連のグループに加入
- オンライン・オフラインイベントへの参加
- 書籍
これに加えて、日本では一般社団法人データサイエンティスト協会なるものがあり、ここから情報を得られるように加入することにしました。
入会方法は上記サイトから参照いただくとして、会員になると以下のようなメリットがあります。
(参照元:入会のご案内 | 一般社団法人 データサイエンティスト協会)
<一般会員>
- 協会が発信するさまざまな情報の先行入手
- 協会の委員会や部会での調査、研究など、活動状況に関する情報をいち早く入手可能
- 協会が主催するイベントなどに参加可能。
- 年会費は無料
<法人会員>
- 協会のロゴの使用許諾
- 当協会の委員会や部会への参加を通じて、情報をいち早く入手可能
- 当協会が主催するイベントなどへ参加可能
- オンライン、オフラインの双方で、会員への情報発信や交流が可能
とこのようなメリットが!
会員種別としては、
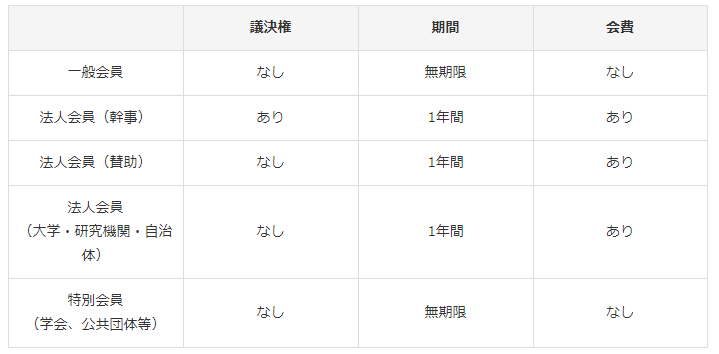
このような形となっています。
まずは一般会員として登録申請してみました。
詳細な活動を見てみると
- セミナー/勉強会
- データサイエンティスト養成講座
- シンポジウム
- データサイエンティストアワード
- DataScientist Social JOURNAL
と豊富な内容となっています。
データサイエンスに特化しているので、以前より気になっていましたが、実際に加入してみて、どんなものなのか確認してみることにします。
追って、コラムで紹介できればと思います。
ではでは。
